Agent architectures#
Instead of hard-coding a fixed control flow, we sometimes want LLM systems that can pick its own control flow to solve more complex problems! This is one definition of an agent: an agent is a system that uses an LLM to decide the control flow of an application. There are many ways that an LLM can control application:
An LLM can route between two potential paths
An LLM can decide which of many tools to call
An LLM can decide whether the generated answer is sufficient or more work is needed
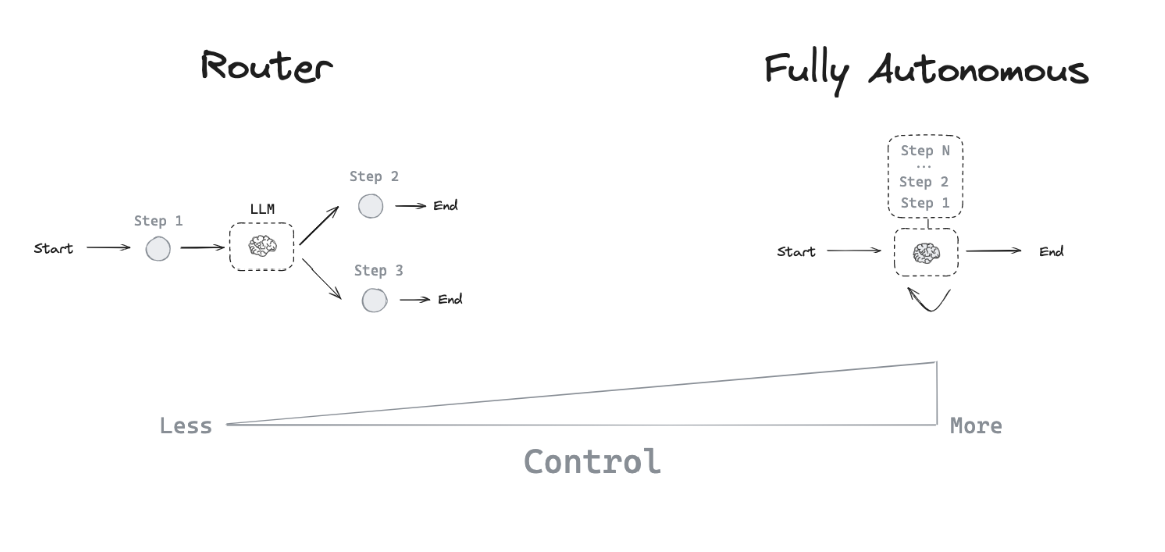
1. Router#
A router allows an LLM to select a single step from a specified set of options. This is an agent architecture that exhibits a relatively limited level of control because the LLM usually governs a single decision and can return a narrow set of outputs. Routers typically employ a few different concepts to achieve this.
Structured Output
Structured outputs with LLMs work by providing a specific format or schema that the LLM should follow in its response. This is similar to tool calling, but more general. While tool calling typically involves selecting and using predefined functions, structured outputs can be used for any type of formatted response. Common methods to achieve structured outputs include:
Prompt engineering: Instructing the LLM to respond in a specific format.
Output parsers: Using post-processing to extract structured data from LLM responses.
Tool calling: Leveraging built-in tool calling capabilities of some LLMs to generate structured outputs.
2. Tool calling agent#
While a router allows an LLM to make a single decision, more complex agent architectures expand the LLM’s control in two key ways:
Multi-step decision making: The LLM can control a sequence of decisions rather than just one.
Tool access: The LLM can choose from and use a variety of tools to accomplish tasks.
Tool calling
Tools are useful whenever you want an agent to interact with external systems. External systems (e.g., APIs) often require a particular input schema or payload, rather than natural language. When we bind an API, for example, as a tool we given the model awareness of the required input schema. The model will choose to call a tool based upon the natural language input from the user and it will return an output that adheres to the tool’s schema.

Memory
Memory is crucial for agents, enabling them to retain and utilize information across multiple steps of problem-solving. It operates on different scales:
Short-term memory: Allows the agent to access information acquired during earlier steps in a sequence.
Long-term memory: Enables the agent to recall information from previous interactions, such as past messages in a conversation.
Planning
an LLM is called repeatedly in a while-loop. At each step the agent decides which tools to call, and what the inputs to those tools should be. Those tools are then executed, and the outputs are fed back into the LLM as observations. The while-loop terminates when the agent decides it is not worth calling any more tools.
3. Custom agent architectures#
While routers and tool-calling agents (like ReAct) are common, customizing agent architectures often leads to better performance for specific tasks. LangGraph offers several powerful features for building tailored agent systems:
Human-in-the-loop
Human involvement can significantly enhance agent reliability, especially for sensitive tasks. This can involve:
Approving specific actions
Providing feedback to update the agent’s state
Offering guidance in complex decision-making processes
Parallelization
Parallel processing is vital for efficient multi-agent systems and complex tasks. LangGraph supports parallelization through its Send API, enabling:
Concurrent processing of multiple states
Implementation of map-reduce-like operations
Efficient handling of independent subtasks
Subgraphs
Subgraphs are essential for managing complex agent architectures, particularly in multi-agent systems. They allow:
Isolated state management for individual agents
Hierarchical organization of agent teams
Controlled communication between agents and the main system
Subgraphs communicate with the parent graph through overlapping keys in the state schema. This enables flexible, modular agent design. For implementation details, refer to our subgraph how-to guide.
Reflection
Reflection mechanisms can significantly improve agent reliability by:
Evaluating task completion and correctness
Providing feedback for iterative improvement
Enabling self-correction and learning
While often LLM-based, reflection can also use deterministic methods. For instance, in coding tasks, compilation errors can serve as feedback. This approach is demonstrated in this video using LangGraph for self-corrective code generation.
By leveraging these features, LangGraph enables the creation of sophisticated, task-specific agent architectures that can handle complex workflows, collaborate effectively, and continuously improve their performance.