Transfer learning#
Transfer learning (TL) is a technique in machine learning (ML) in which knowledge learned from a task is re-used in order to boost performance on a related task.
A domain \(\mathcal{D}\) consists of: a feature space \(\mathcal{X}\) and a marginal probability distribution \(P(X)\), where \(X=\{x_1,...,x_n\}\in \mathcal{X}\). Given a specific domain, \(\mathcal{D}=\{\mathcal{X},P(X)\}\), a task consists of two components: a label space \(\mathcal{Y}\) and an objective predictive function \(f:\mathcal{X}→\mathcal{Y}\).The function \(f\) is used to predict the corresponding label \(f(x)\) of a new instance \(x\). This task, denoted by \(T=\{\mathcal{Y},f(x)\}\), is learned from the training data consisting of pairs \(\{x_i,y_i\}\),where \(x_i\in\mathcal{X}\) and \(y_i \in\mathcal{Y}\).
Given a source domain \(\mathcal{D}_S\) ,and learning task \(\mathcal{T}_S\), a target domain \(\mathcal{D}_T\) and learning task \(\mathcal{T}_T\), where \(\mathcal{D}_S\ne\mathcal{D}_T\), or \(\mathcal{T}_S\ne \mathcal{T}_T\). Transfer learning aims to help improve the learning of the target predictive function \(f_T(.)\) in \(\mathcal{D}_T\) using the knowledge in \(\mathcal{D}_S\) and \(\mathcal{T}_S\).
[!NOTE]
If the input pictures for your new task don’t have the same size as the ones used in the original task, you will usually have to add a preprocessing step to resize them to the size expected by the original model. More generally, transfer learning will work best when the inputs have similar low-level features.
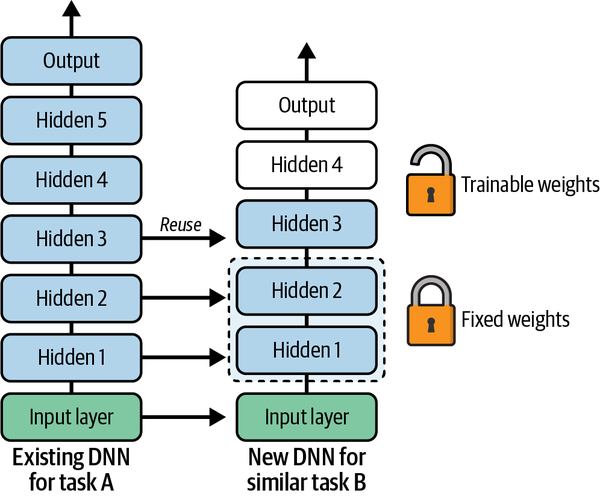
Try freezing all the reused layers first (i.e., make their weights non-trainable so that gradient descent won’t modify them and they will remain fixed), then train your model and see how it performs. Then try unfreezing one or two of the top hidden layers to let backpropagation tweak them and see if performance improves. The more training data you have, the more layers you can unfreeze. It is also useful to reduce the learning rate when you unfreeze reused layers: this will avoid wrecking their fine-tuned weights.
If you still cannot get good performance, and you have little training data, try dropping the top hidden layer(s) and freezing all the remaining hidden layers again. You can iterate until you find the right number of layers to reuse. If you have plenty of training data, you may try replacing the top hidden layers instead of dropping them, and even adding more hidden layers.
1. Feature Extraction#
Use the representations learned by a previous network to extract meaningful features from new samples. You simply add a new classifier, which will be trained from scratch, on top of the pretrained model so that you can repurpose the feature maps learned previously for the dataset.
You do not need to (re)train the entire model. The base convolutional network already contains features that are generically useful for classifying pictures. (The pre-model is frozen )However, the final, classification part of the pre-trained model is specific to the original classification task, and subsequently specific to the set of classes on which the model was trained.
2. Fine-Tuning#
Unfreeze a few of the top layers of a frozen model base and jointly train both the newly-added classifier layers and the last layers of the base model. This allows us to “fine-tune” the higher-order feature representations in the base model in order to make them more relevant for the specific task.
[!NOTE]
This should only be attempted after you have trained the top-level classifier with the pre-trained model set to non-trainable. If you add a randomly initialized classifier on top of a pre-trained model and attempt to train all layers jointly, the magnitude of the gradient updates will be too large (due to the random weights from the classifier) and your pre-trained model will forget what it has learned.
Detailed codes and examples can be seen in: