Introduction to Deep learning#
1. 1. Feed-Forward Neural Nets#
1.1. 1.1. Perceptrons#
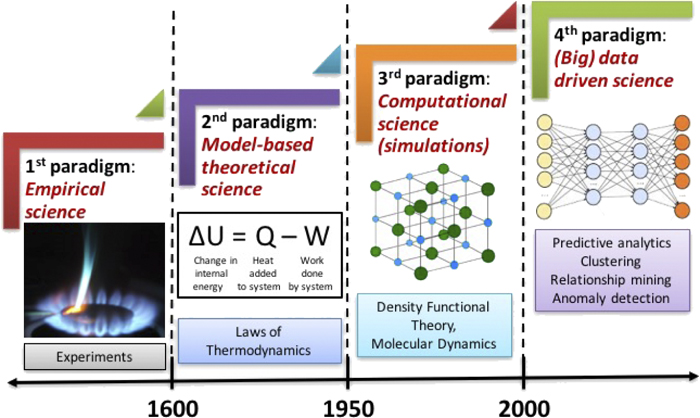
Perceptrons were invented as simple computational models of neurons. A single neuron typically has many inputs (dendrites), a cell body, and a single output (the axon). Echoing this, the perceptron takes many inputs and has one output.
A perceptron consists of a vector of weights \(w=[w_1...w_m]\), one for each input, plus a distinguished weight \(b\), called the bias. We call \(w\) and \(b\) the parameters of the perceptron. More generally, we use \(\Phi\) to denote parameters, with \(\phi_i\in \Phi\) the \(i_{th}\) parameter. For a perceptron \(\Phi={w\cup b}\)
So, for binary classification problem, with these parameters the perceptron computes the following function:
Dataset split
\(\left\{\begin{aligned}&\text{training set}\rightarrow\text{It is used to adjust the parameters of the model.}\\&\text{validation set}\rightarrow\text{It is used to test the model as we try to improve it.}\\&\text{test set}\rightarrow\text{prevents from a program that works on the development set but not on yet unseen problems.}\end{aligned}\right.\)
Learning algorithm
Set initial weights equal 0, that is b and all of the w
for N iterations, or until the weights do not change.
(a). for all training example \(x^k\) with answer \(a^k\)
i. if \(a^k-f(x^k)=0 \) continue.
ii. else for all weights \(w_i\), \(\Delta w_i=(a^k-f(x^k))x_i\)
[!NOTE]
This weights updating algorithm is based on the gradient descent.
\[\begin{split} J(x)=\frac{1}{2m}\sum_i^m(y-f(x))^2=\frac{1}{2m}\sum_i^m(y-wx)^2\\ \frac{\partial{J(x)}}{\partial{w}}=-\frac{1}{m}\sum_i^m(y-wx)x \end{split}\]
We go through the training data multiple times. Each pass through the data is called an epoch.
1.2. 1.2. Cross-entropy Loss Functions for Neural Nets#
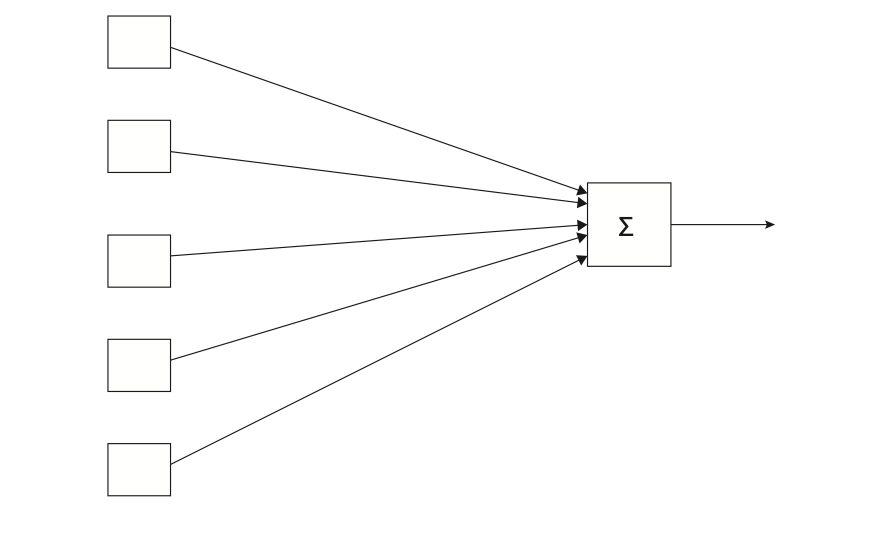
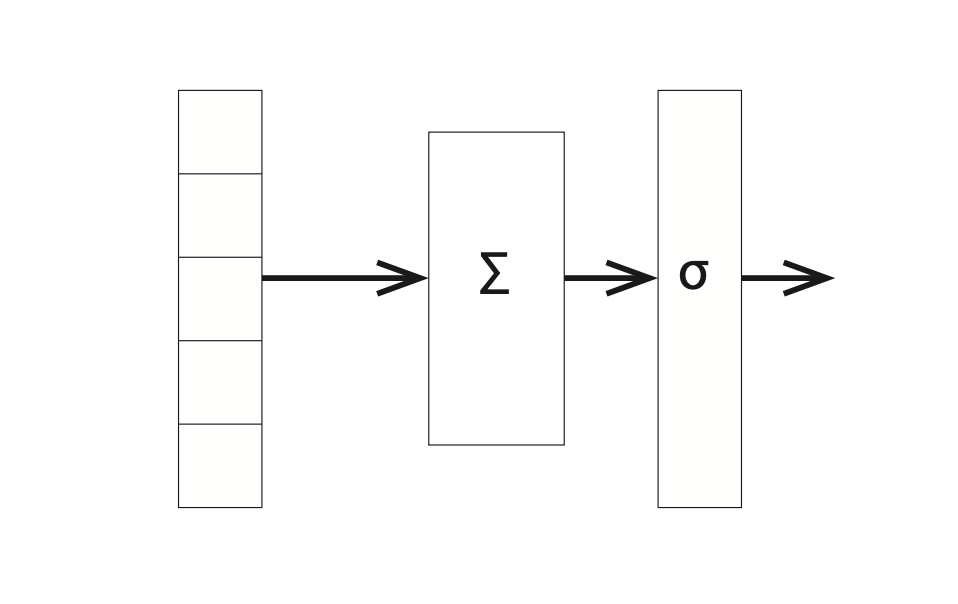
In its infancy, a discussion of neural nets (we henceforth abbreviate as NN) would be accompanied by diagrams much like that in Figure 1.2 with the stress on individual computing elements (the linear units). These days we expect the number of such elements to be large so we talk of the computation in terms of layers — a group of storage or computational units that can be thought of as working in parallel and then passing values to another layer. Figure 1.3 is a version of Figure 1.2 that emphasizes this view. It shows an input layer feeding into a computational layer.
Gradient function
In learning model parameters, our goal is to minimize loss.
Because we have multi-classification task, currently our network of Figure 1.4 outputs a vector of values, one for each linear unit, and we choose the class with the highest output value. We now change our network so that the numbers output are (an estimate of) the probability distribution over classes. A probability distribution is a set of non-negative values that sum to be one. Because our neuron network output are numbers which contain both negative and positive. We want to map them into the probability distribution.
Softmax function:
It is also useful to have a name for the numbers leaving the linear units and going into the softmax function. These are typically called logits \(\longrightarrow\) a term for un-normalized numbers that we are about to turn into probabilities using softmax.
Cross-entropy loss function
Now we are in a position to define our cross-entropy loss function \(X\):
Let’s see why this is reasonable. First, it goes in the right direction. If \(X\) is a loss function, it should increase as our model gets worse. Well, a model that is improving should assign higher and higher probability to the correct answer. So we put a minus sign in front so that the number gets smaller as the probability gets higher. Next, the log of a number increases/decreases as the number does. So indeed, \(X(\Phi,x)\) is larger for bad parameters than for good ones.
1.3. Derivatives and Stochastic Gradient Descent#
We can see that \(b_j\) changes loss by first changing the value of the logit \(l_j\) , which then changes the probability and hence the loss. Let’s take this in steps.
[!NOTE]
The problem here is that this algorithm can be very slow, particularly if training set is large. We typically need to adjust the parameters often since they are going to interact in different ways as each increases and decreases as the result of particular test examples. Thus in practice we almost never use gradient descent but rather stochastic gradient descent, which updates the parameters every m examples, for m much less that the size of the training set. A typical m might be twenty. This is called the batch size
In general, the smaller the batch size, the smaller the learning rate \(\mathcal{L}\) should be set. The idea is that any one example is going to push the weights toward classifying that example correctly at the expense of the others. If the learning rate is low, this does not matter that much, since the changes made to the parameters are correspondingly small. Conversely, with larger batch size we are implicitly averaging over m different examples, so the dangers of tilting parameters to the idiosyncrasies of one example are lessened and changes made to the parameters can be larger.
for \(j\) from 0 to 9 set \(b_j\) randomly (but close to zero)
For \(j\) from 0 to 9 and for \(i\) from 0 to 783 set \(w_{i,j}\) similarly
until development accuracy stops increasing
(a) for each training example k in batches of m examples
i.do the forward pass using Equations 7
ii.do the backward pass using Equations 9, 10
iii.every m examples, modify all \(\Phi_s\) with the summed updates
(b) compute the accuracy of the model by running the forward pass on all examples in the development corpus
output the from the iteration before the decrease in development accuracy.
2.Convolutional Neural Networks#
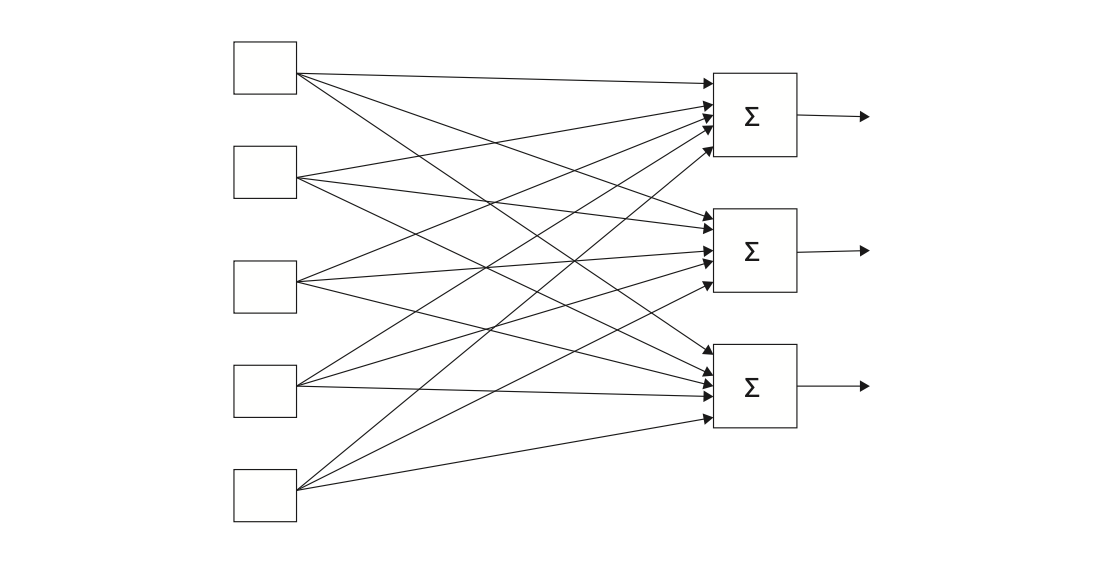
The NNs considered so far have all been fully connected. That is, they have the property that all the linear units in a layer are connected to all the linear units in the next layer.However, there is no requirement that NNs have this particular form. We can certainly imagine doing a forward pass where a linear unit feeds its output to only some of the next layer’s units. One special case of partially connected NNs is convolutional neural net- works. Convolutional NNs are particularly useful in computer vision,
1. 2.1. The Convolution Operation#
Suppose we are tracking the location of a spaceship with a laser sensor. Our laser sensor provides a single output \(x(t)\), the position of the spaceship at time \(t\). Both \(x\) and \(t\) are real valued, that is, we can get a different reading from the laser sensor at any instant in time.
Now suppose that our laser sensor is somewhat noisy. To obtain a less noisy estimate of the spaceship’s position, we would like to average several measurements. Of course, more recent measurements are more relevant, so we will want this to be a weighted average that gives more weight to recent measurements. We can do this with a weighting function \(w(a)\), where \(a\) is the age of a measurement. If we apply such a weighted average operation at every moment, we obtain a new function s providing a smoothed estimate of the position of the spaceship:
In convolutional network terminology, the first argument (in this example, the function \(x\)) to the convolution is often referred to as the input, and the second argument (in this example, the function \(w\)) as the kernel. The output is sometimes referred to as the feature map.
Because the data is always discrete, so the discrete convolution can be defined.
[!Tip]
Proof of commutative
\((f*g)(x) = \int f(t)g(t-x)dt \Rightarrow \mu = x-t\)
\((f*g)(x) = \int f(x-\mu)g(-\mu)d(-\mu)\\=\int f(x-\mu)g(\mu)d\mu \\= \int g(\mu)f(x-\mu)d\mu\)
So, \((f*g)(x)= (g*f)(x)\)
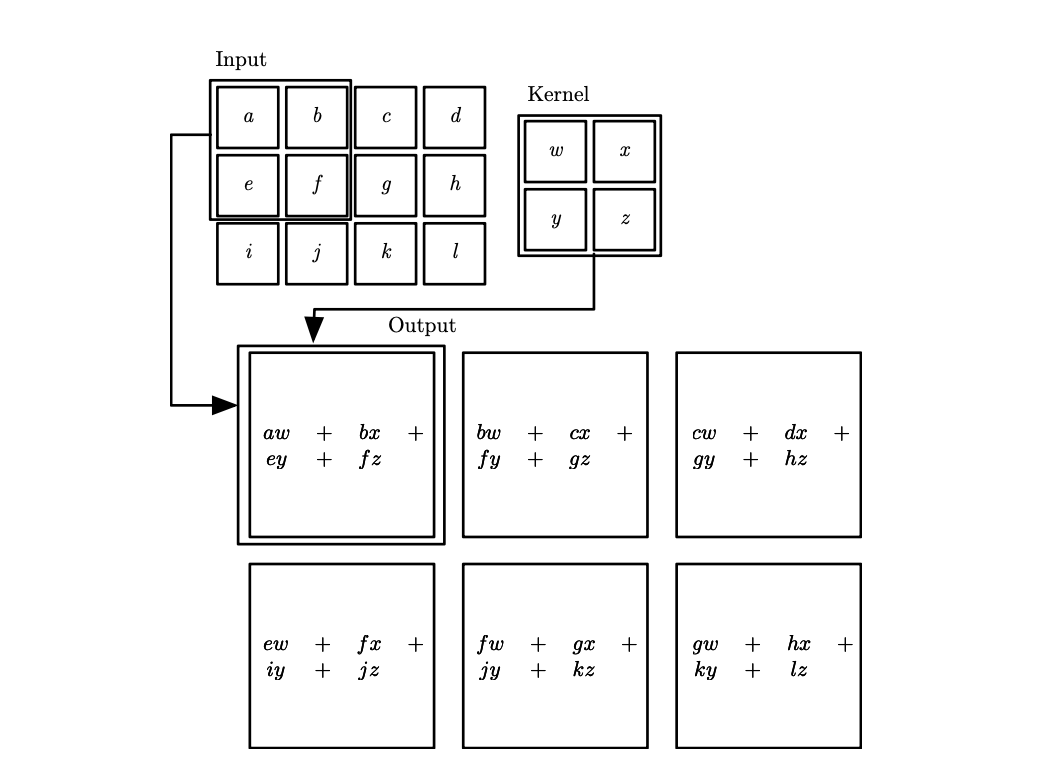
Many neural network libraries implement a related function called the cross-correlation, which is the same as convolution but without flipping the kernel:
2. 2.2.Motivation#
Convolution leverages three important ideas that can help improve a machine learning system:
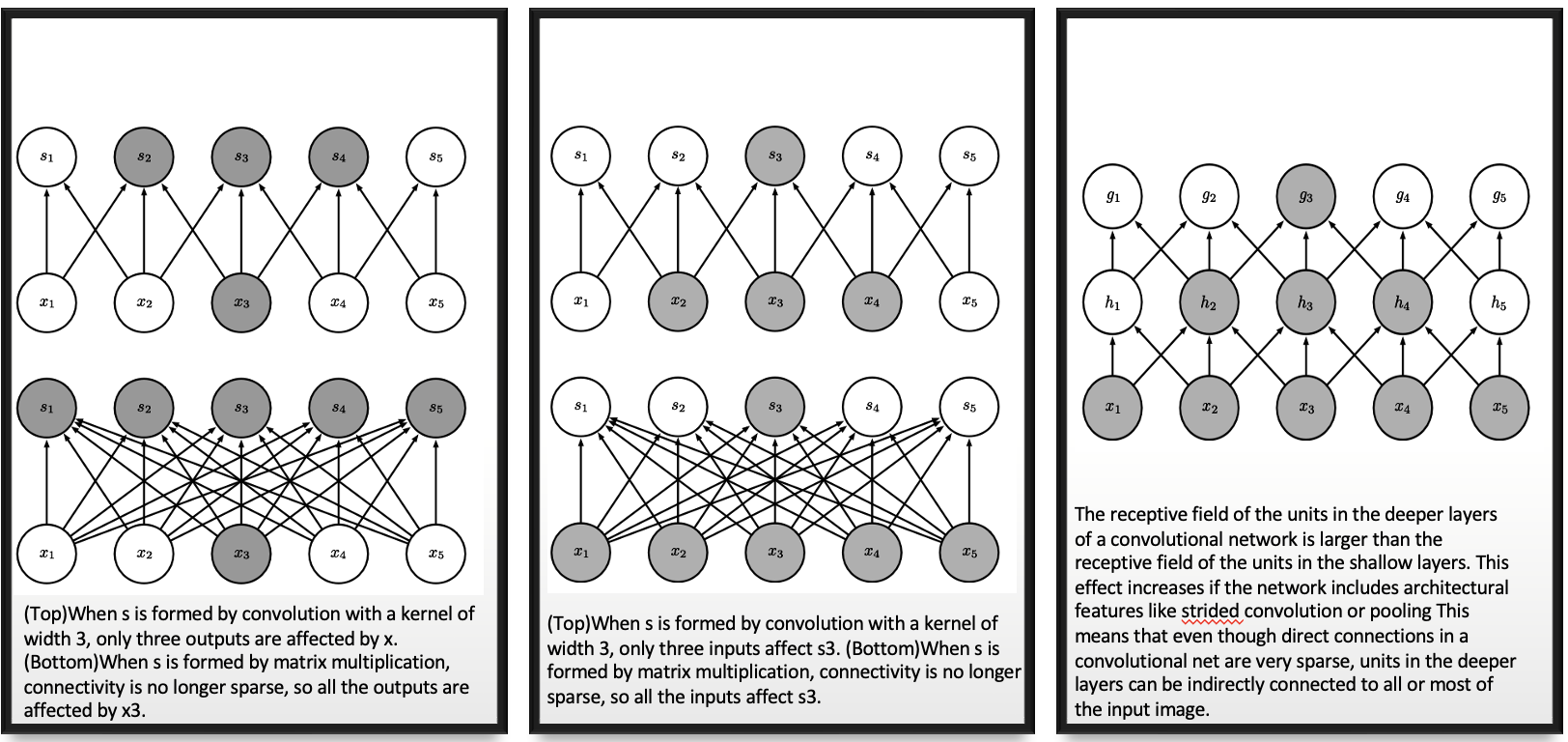
Sparse interactions
Suppose for full connected dense neuron network, we have \(m\) inputs and \(n\) outputs, the matrix multiplication requires \(m\times n\) parameters, and the algorithms used in practice have \(O(m\times n)\) runtime.
If we limit the kernel (the number of connections each output) to \(k\), such sparse connections only requires \(k\times n\) parameters and \(O(k\times n)\) runtime.
Parameter sharing
The parameter sharing used by the convolution operation means that rather than learning a separate set of parameters
for every location, we learn only one set. This does not affect the runtime of forward propagation—it is still O(k× n)—but it does further reduce the storage requirements of the model to k parameters.
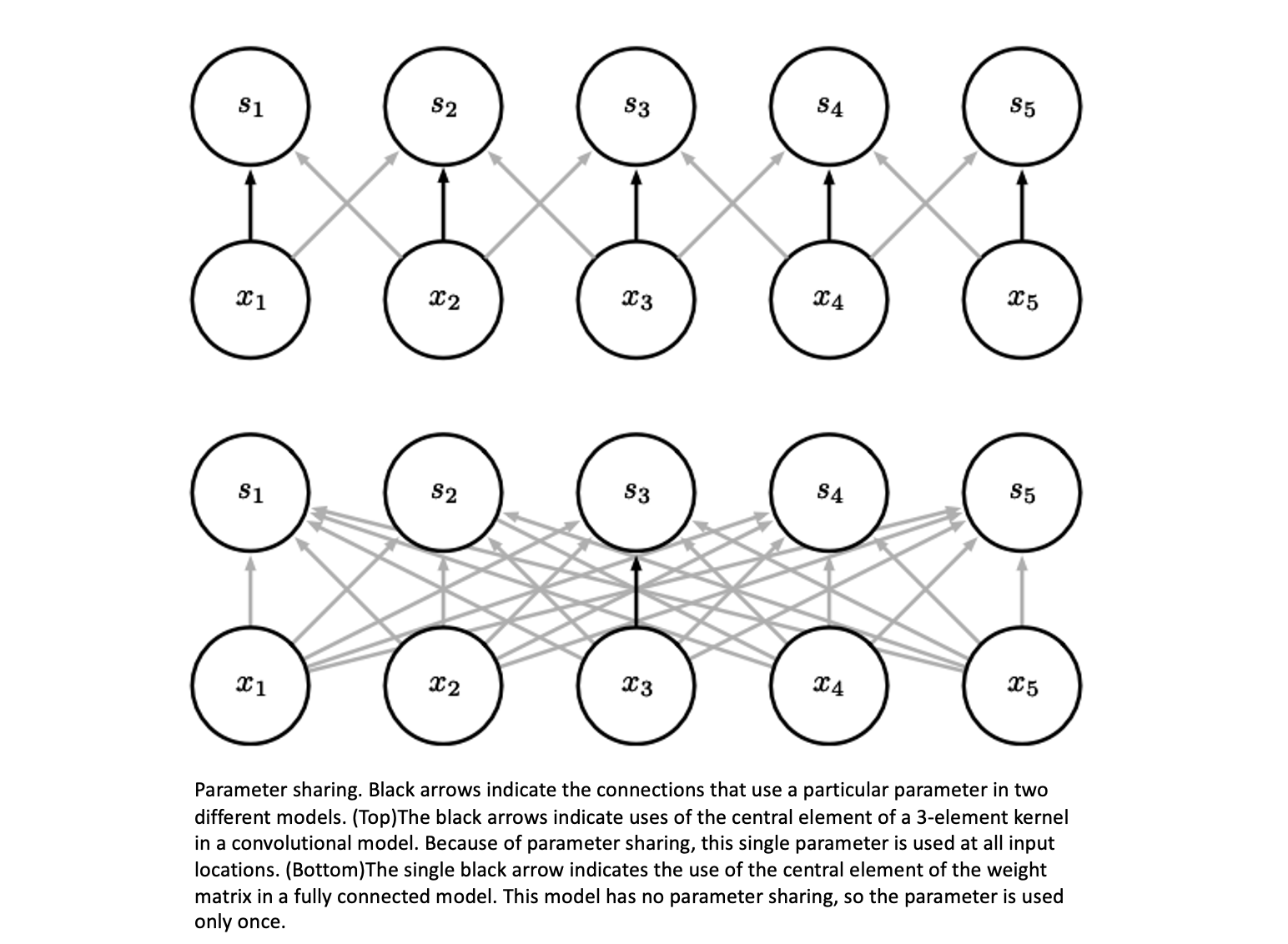
Figure 2.3Graphical depiction of how parameter sharing Equivariant
In the case of convolution, the particular form of parameter sharing causes the layer to have a property called equivariance to translation.
\(((T_a f) * g)(x) = \int f(t - a)\, g(x - t)\, dt\), \(u = t - a \quad\Rightarrow\quad t = u + a,\quad dt = du\)
\(\begin{aligned} ((T_a f) * g)(x) &= \int f(u)\, g(x - (u + a))\, du \\ &= \int f(u)\, g((x - a) - u)\, du \\ &= (f * g)(x - a) \end{aligned}\)
\((f * g)(x - a) = (T_a (f * g))(x)\)
So, \((T_a f) * g = T_a(f * g)\)
3. 2.3. Pooling#
Pooling helps to make the representation approximately invariant to small translations of the input.
[!NOTE]
Difference between invariance and equivariance
Invariance: \(T(f(x)) = f(x)\)
Equivariance: \(Tf(x)= f(T(x))\)